
分享一个本地通用70亿+130亿本地运行大模型,可支持开启联网搜索组合生成文章,可过ai检测。可配合火车头根据关键词批量入库使用。

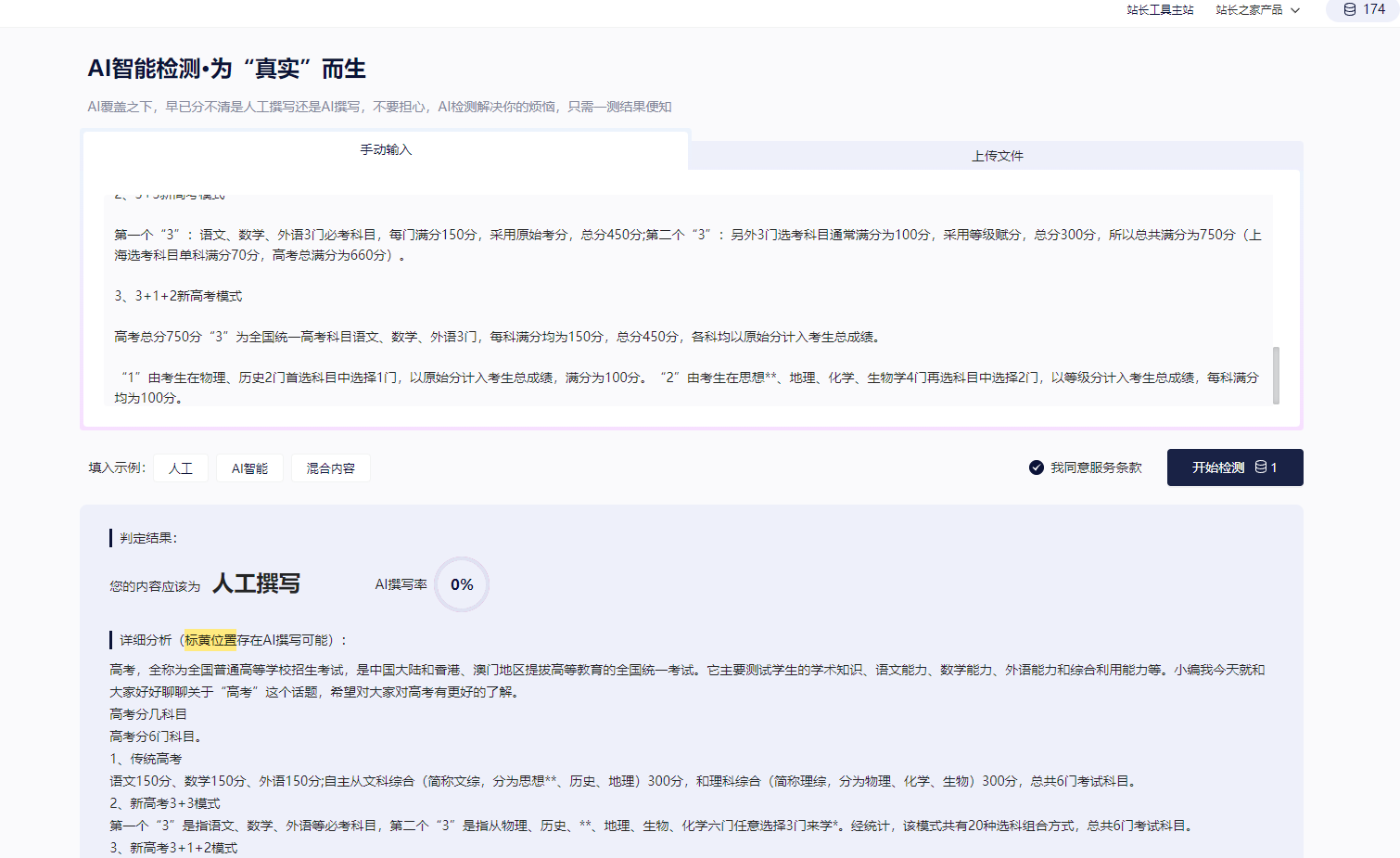
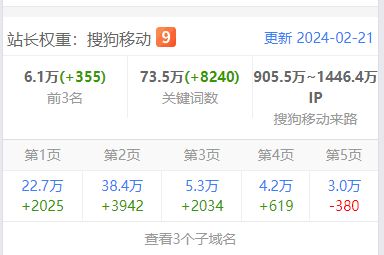
测试配合做seo效果比较好,自己测试网站,因为自己是做搜狗排名测试,效果还不错,三个月搜狗的词库涨的也比较猛。
硬件准备:
显存8G+ 比如2060s,2070,2080..3060…3090是性价比最高的显卡
2. 软件环境
操作系统Win11/Win10
其他基本不需要自己准备。
3. 使用方法
首先,获取软件包并解压。最好是解压在某个盘的根路径下面。如果是子路径,注意不要用中文和空格。
特色:
无需任何其他环境配置,只需硬件跟上,解压即可使用,无需安装其他扩展。
使用:
点击run-web.bat, 启动7b-4bit量化。出现窗口,即可聊天和web端在线生成!
如果要运行api端,进行火车头采集,则只需要点击:运行全部的采集api,这样就会自动开启api根据火车头关键词自动生成文章模式。
如果要开启火车头采集,必须开启phpstudy,并且启动ngnix,并且打开火车头运行,根据测试的ai采集规则进行自行写规则控制,然后根据自己的站点选择适当的网站发布模块,即可实现实时网站自动发布。
默认运行的api是开启三个端口,分别是8001,8002,8003端口,即三个线程,经过测试三个线程的效率和生成文章的稳定性是最好的。如果你要改端口号,则需要分别打开api.py,api2.py,api3.py里面查找端口
并且打开phpstudy里面 D:\phpstudy_pro\Extensions\Nginx1.15.11\conf\vhosts 下api.com_80.conf 修改反向代理的数据
如果需要修改部分生成的命令和替换数据,可以修改phpstudy里面的:D:\phpstudy_pro\WWW\ api.php 文件,里面可以替换过滤生成的数据,包括生成的违规词过滤,年份数据过滤等等
你也可以发挥自己的所长,进行修改属于自己的风格。
目前测试模型生成效果比较好的有:教育,旅游,宠物,问答,金融,游戏攻略,法律等行业,不支持的行业为:电影,视频,下载等
训练的数据来自:百度百科,百度知道,今日头条,头条问答,搜狗百科,政府官方数据,中国民法典,刑法,法律文书,教辅,牛津词典,新华词典,汉语词典,国家院校,科普平台等
数据训练的为:8300万数据,底座为gpt3.5的大模型运行逻辑,并且去除大部分的ai化,可很好适用网站的文章发布,但是切勿用于违法内容生成和实时新闻生成,否则责任自担!
本程序为全开源程序,全部代码可修改商用。但是切勿使用非法用途!


